Dlaczego hosting powinien być krokiem numer jeden w optymalizacji WordPressa
Spis treści
Rozwiń spis treści
Popularny schemat, który nie działa
W środowisku WordPressowym funkcjonuje pewien powtarzalny schemat: klient zgłasza, że strona jest wolna. Specjalista zabiera się za profilowanie, analizę zapytań do bazy danych, odchudzanie pluginów. Hosting? Zostawiamy. Przecież najpierw trzeba zoptymalizować to, co mamy.
Brzmi rozsądnie - i w wielu przypadkach jest słuszne. Ale jest granica, za którą to podejście staje się fundamentalnie błędne.
Ta granica przebiega tam, gdzie serwer na prostej stronie biznesowej - zwraca TTFB na poziomie kilku sekund bez cache’owania.
Strona o takiej charakterystyce na porządnym hostingu powinna osiągać TTFB na poziomie 200-300 milisekund bez żadnego cache’a. Google za akceptowalną granicę uznaje 800ms. Nie widziałbym tu większego problemu, gdyby TTFB oscylowało w granicach 800-1200ms, bo dla wielu osób to wciąż akceptowalny kompromis w relacji do ceny.
Ale 3-4 sekundy? To jest kilkaset procent powyżej normy. I żadna ilość optymalizacji kodu tego nie naprawi.
Tykająca bomba
Powiedzmy, że na takim hoście uda się wycisnąć przyzwoite wyniki za pomocą cache. Strona się ładuje, klient jest zadowolony.
Ale nigdy nie osiągniemy cache hit ratio na poziomie 100%.
A gdy proces optymalizacji zostanie zakończony i zniknie nad nim ciągły nadzór, wystarczy jedno z poniższych, żeby cała konstrukcja się posypała:
- Nowy kanał pozyskania ruchu z parametrem w URL, którego cache nie ignoruje
- Nowy plugin lub aktualizacja pluginu powodująca konflikt z konfiguracją cache
Już za kilka miesięcy może się okazać, że właściciel strony puści kosztowną kampanię reklamową, a klienci zamiast dostawać stronę z cache, będą na nią czekać po 4 sekundy.
Kampania będzie miała kosmiczny bounce rate z powodu jednego drobnego przeoczenia.
Cała inwestycja w optymalizację - na marne.
Bo pod spodem wciąż jest fatalny serwer.
Eksperyment - ten sam kod, dwa serwery
Ostatnio podjąłem się optymalizacji jednego z serwisów. Wyjściowo stał na bardzo słabym hostingu, więc od samego początku postawiłem sprawę jasno: nie ma sensu ładować się w optymalizację, jeśli zostawimy stronę na obecnym serwerze.
Umówiliśmy się na migrację na porządny hosting, a w międzyczasie zrobiłem optymalizację na środowisku dev. Po jej zakończeniu puściłem pomiary na obu środowiskach - żeby mieć twarde dane.
Wyniki na starym hostingu
| Próba | Stary motyw (bez optymalizacji) | Nowy motyw (po optymalizacji) |
|---|---|---|
| 1 | 2.16s | 2.29s |
| 2 | 2.55s | 2.15s |
| 3 | 2.52s | 2.85s |
| 4 | 2.52s | 3.45s |
| 5 | 3.47s | 2.52s |
| 6 | 4.14s | 2.28s |
| 7 | 4.24s | 2.64s |
| 8 | 2.93s | 3.72s |
| 9 | 2.90s | 2.43s |
| 10 | 2.61s | 2.33s |
| 11 | 2.89s | 2.47s |
| 12 | 2.36s | 2.13s |
| 13 | 2.44s | - |
| Średnia | 2.90s | 2.61s |
10% szybciej. Dalej 326% powyżej zalecanej granicy dla TTFB.
Warto zaznaczyć, że Query Monitor pokazywał o prawie sekundę szybszy czas niż header cfOrigin z Cloudflare.
Co to oznacza? Strona generowała się w PHP, a później jeszcze sekundę czekała na ‘wyjście’ z serwera.
W Query Monitorze widać było wyraźną różnicę na requestach do bazy danych - optymalizacja była wykonana poprawnie i działała. Ale przeładowany serwer dodawał tak duży narzut, że cała robota finalnie przekładała się na skromne 10% poprawy, z TTFB wysoko powyżej norm.
Powiedz szczerze - zapłaciłbyś półtorej dniówki programisty za taki progres?
Ja raczej niechętnie.
Wyniki na docelowym hostingu
Te same wersje motywu, ten sam kod - ale tym razem już na odpowiednim serwerze.
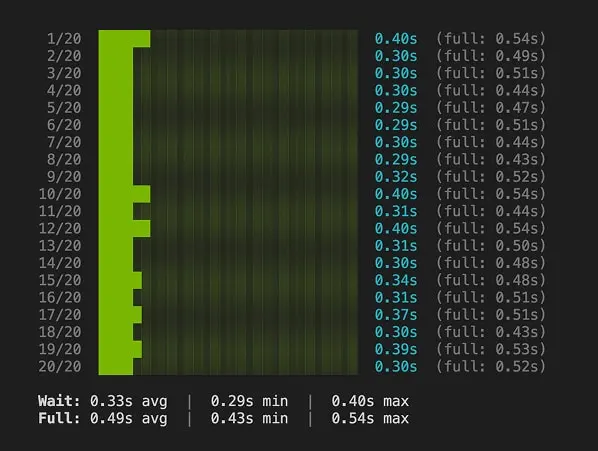
Stary motyw na nowym hoście:
Nowy motyw na nowym hoście:
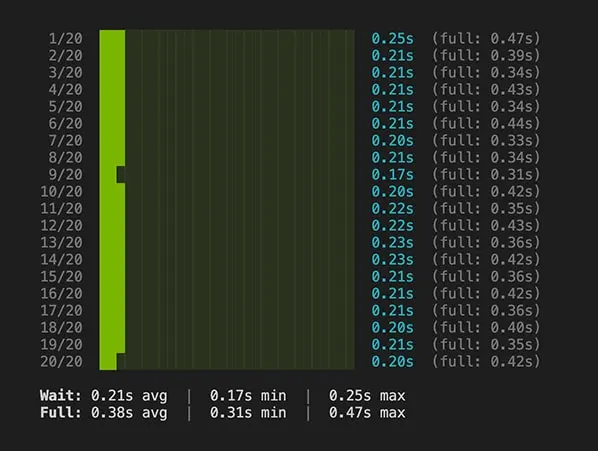
Oprócz pełnego TTFB mierzyłem też sam wait time serwera - czyli ile rzeczywiście serwer przetwarzał request: PHP + Nginx.
Pełne TTFB: 0.38s vs 0.49s
Wait time serwera: 0.21s vs 0.33s
22% poprawy i TTFB z zapasem ponad 400ms do rekomendowanej granicy.
Jeśli pominiemy czas połączenia i skupimy się na samym procesie PHP + Nginx, serwer podaje stronę 36% szybciej.
To już wygląda trochę lepiej niż 10% i czas powyżej 2.5s.
Najpierw fundament, potem optymalizacja
Dopiero po takiej optymalizacji i potwierdzeniu realnych wyników przystępuję do konfiguracji cache.
Bo nawet gdy nie przewidzę każdego scenariusza - dalej będzie względnie dobrze.
Wiem też, że nawet zalogowany użytkownik (który nie dostanie strony z cache) będzie mógł szybko i wygodnie korzystać ze strony.
Wróćmy do liczb
Popatrzmy na to z perspektywy biznesowej.
Jeśli stary serwer potrafił regularnie dokładać narzut na poziomie jednej sekundy (mierzoną jako różnica między timingiem Query Monitor a cfOrigin), to nawet inwestując kilkaset tysięcy złotych i przepisując aplikację kompletnie od zera, nie bylibyśmy w stanie nawet w przybliżeniu zbliżyć się do wyników starej wersji motywu serwowanej na lepszym hostingu.
Zawsze ogranicza nas fatalny serwer.
Może czasem będzie lepiej, może gorzej, ale próbując oszczędzić na porządnej infrastrukturze, możemy wpaść w pętlę prac programistycznych, które nigdy nie będą miały happy endu.
A postępując odwrotnie?
Sama migracja poprawia performance z 2.90s na 0.49s. To prawie 6 razy szybciej.
Zero analiz.
Zero planowania refaktoru.
Jedna szybka migracja na dobry hosting.
Jeden dzień - i mamy wynik.
Koszty mogą wydawać się większe, jeśli zestawimy je w tabeli porównując wyłącznie cennik hardware’u.
Ale jeśli doliczymy koszty programistów, może się okazać, że sama migracja jest wielokrotnie tańsza.
Koniec tolerancji dla słabych hostingów
Lata zabijania się ceną i brudnych sztuczek na rynku hostingowym doprowadziły do sytuacji, gdzie część osób przyjmuje za pewnik, że host może być tani i wolny. I po prostu to akceptuje.
Tak po prostu musi być z WordPressem!
Przymykamy oko i staramy się maskować to cache’em. A to prosta droga do kompletnego blamażu WordPressa jako platformy.
Popatrz na to od strony biznesu, który rozważa zbudowanie strony na WordPressie.
Wyobraź sobie, że jeden z decydentów trafia na kurs o optymalizacji i widzi, że żeby jego prosta strona biznesowa była względnie szybka, musi zaprząc specjalistę od optymalizacji i poświęcić na ten proces trzy miesiące.
Jak myślisz - co zrobi?
Wybierze WordPressa, czy pójdzie w stronę Astro, Next.js, albo dowolnej innej technologii, gdzie taki problem nie istnieje?
Akceptując taki stan rzeczy, my jako deweloperzy WordPressa sami strzelamy sobie w kolano.
Normalizujemy patologię wydajnościową i uczymy klientów, że “to tak po prostu wygląda”. A potem dziwmy się, że WordPress traci udziały w rynku.
Oczywiście zawsze powinniśmy dążyć do zachowania dobrych wzorców projektowych i rozwiązywania problemów na etapie projektowania - a nie łatać je później, gdy strona już zawali wyniki.
Ale jeśli stan wejściowy naszego projektu kompletnie przekracza dopuszczalne normy z powodu złej infrastruktury, to jest to nasza odpowiedzialność, by wyznaczyć jasno granicę racjonalnej optymalizacji i powiedzieć: stop.
Nie tolerujmy tego.
To właśnie z tą myślą stworzyłem SHIFT64 - bo uważam, że porządna infrastruktura powinna być fundamentem, a nie luksusem.
Jeśli chcesz zgłębić temat optymalizacji WooCommerce, zapraszam też do artykułu Prosta recepta na szybki WooCommerce oraz Testowanie WooCommerce przy pomocy testów k6.
Jakie jest Twoje zdanie? Jestem ciekawy, czy zgodzicie się chociaż w części z moimi tezami.
